Given When Then
This post was originally written while I was at LShift / Oliver Wyman

There are, of course, a large number of techniques described as being The Way To Do Software Engineering. I’m sure I’ve not come across them all but the ones I know about and use currently include at least: Impact mapping, Pert charts, Gantt charts, Personas, Wardley mapping, Agile, DSDM, MoSCoW, SMART, INVEST and BDD (I’ve not done Prince for two decades at least), and then actually writing the software in Sprints which, in turn, includes: PRL, DDD, Unit Testing, Integration Testing (‘Continuous’ or otherwise), TDD, and Fuzz testing, etc. It’d be nice to bring all of these into some kind of coherent model we can utilised to produce correct and usable software.
Books have been written about each of the above techniques and more which I’m not going to repeat here though it may be useful to quickly skim through at least some of them. I’m bound to say something slightly contentious or incomplete in these summaries; if I do then I defer to the greater literature.
Impact mapping covers the ‘Why are we bothering to do this?’ of the system:
- Four main concepts: Goal/Why, Actor/Who, Impact/How (the Actors change their behaviour or do their task), Deliverable/What
- Personas are useful descriptions of various aspects or variations of the Actors
- Agile Stories can then be read directly out of the Impact Map. I.e. “As an [actor/who,] I want to [deliverable/what], so that I can [impact/how].”
Agile was publicised at least as a manifesto for communication and rapid iteration. Early versions of the manifesto continue to be criticised, but this is unfair as ‘Pragmatic Agile’ techniques like DSDM (Dynamic System Development Method) are now well developed.
- Software is manufactured in a series of timeboxed Sprints or Iterations (in the order of weeks rather than months or years) with a retrospective and refocus at the end of each sprint.
- During a Sprint a list of Stories is considered for solving. Ergo if a story is too big for a sprint, or it will take a whole sprint (or, even, more than a few days) then we re-label it as an ‘Epic’ (really just a very big story) and break it down into more manageable parts (which we then call Stories – i.e. they should still be expressed in the ‘as a [], I want to [], so I can [*]" triple).
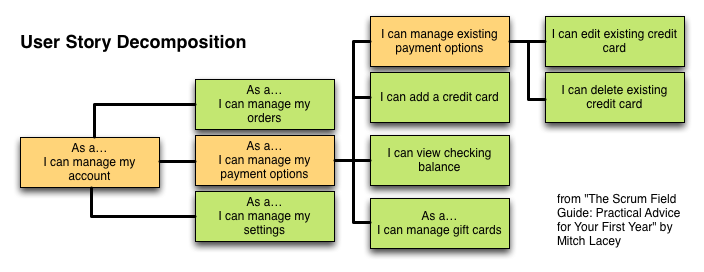
Possibly a good way to break down an Epic is to write out all the acceptance criteria (see below); if done well it’s likely the criteria can be grouped into orthogonal sets where each set is likely a candidate for a story of its own. Acronyms like SMART and INVEST are often thrown around at this point. SMART has many possible meanings, but a common one is ‘Specific, Measurable, Achievable, Relevant, and Time-bound’ – but there are a lot of tautologies in there (how can something be either Time-bound or Achievable without being both Measurable and Specific?). INVEST seems more useful: ‘Independent, Negotiable, Valuable, Estimable, Small, and Testable’.
Note that slide 6 on this deck is misleading:
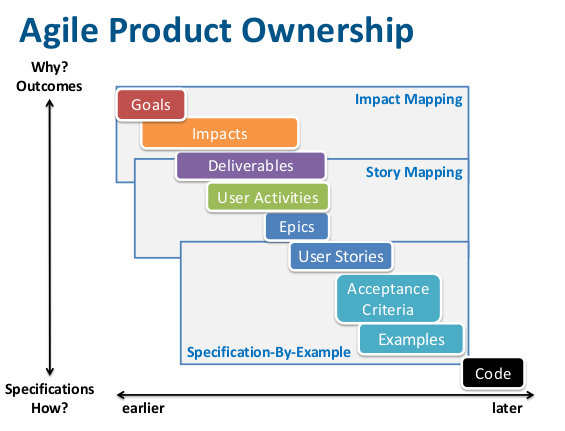
It seems to indicate a straight line top left to bottom right that one could execute in order and good software just pops out at the end. But really it’s the grey background boxes that show the correct timeline: i.e. everything overlaps. And as for suggesting there should be a tiny ‘do the coding’ box at the end, well, let’s move on…
BDD (Behaviour Driven Development) simply describes the set of Acceptance Criteria and/or Scenarios that should be attached to each story to give the ‘Definition Of Done’:
- GIVEN a condition, WHEN something is done, THEN something happens
Wardley maps are a way of modelling what parts of the system are most visible to the user; perhaps giving an indication of priority for tackling them:
- Graph of ‘real things’ and ‘depends-on’ links between them
- Things tend to be nouns
- The things more visible to the user, the ‘User Anchors’, are the Deliverable/What/Epic/Story we saw above – which, in turn, are a set of Behaviours.
- The things less visible to the user are likely to be the underlying substrate of system units and integrations that make those Behaviours possible.
Planning is quite useful:

Given the set of stories we’ve now identified for the system, and the relationships between them, we need to decide in which order to tackle the stories so we can have the best chance of producing something useful within the allocated time frame and budget. So at this point we can use a MoSCoW (Must, Should, Could, Won’t) technique to prioritise each feature and end up with the PRL (Prioritised Requirements List).
We can now use the PRL to populate the sprints directly or, as an extra bonus, create a Pert chart and a (probably aspirational) predictive Gantt chart to plot our course.
Software that satisfies the set of stories is, in some way, made up of units of capability and integrations between those units. In vague terms unit tests examine the behaviour of each unit in isolation and integration tests check how the units behave when communicating with each other and the glue between them (no surprises there). But it may be that producing a behaviour takes a whole collection of units and, likewise, a unit may be fundamental to a whole set of behaviours. So we may end up with a matrix of behaviours against units and integrations – i.e. a many-many join from behaviours to unit and integration tests
This may all seem like a huge palaver, and indeed it will be if one is tempted to follow all the techniques to the letter! But in practical development, and by looking at the scale of the problem, it’s often easy to do at least some of these techniques in one’s head. That is: each technique should be followed ONLY if it adds value to the current project, and fastidiously following all of them may even get in the way. There’s an interesting balance to reach:
none of these techniques are strictly necessary, and following all of them is no guarantee of success – however, the correct techniques used at the appropriate time can greatly improve one’s chance of success.
So do we have a coherent model now? Perhaps something like this:
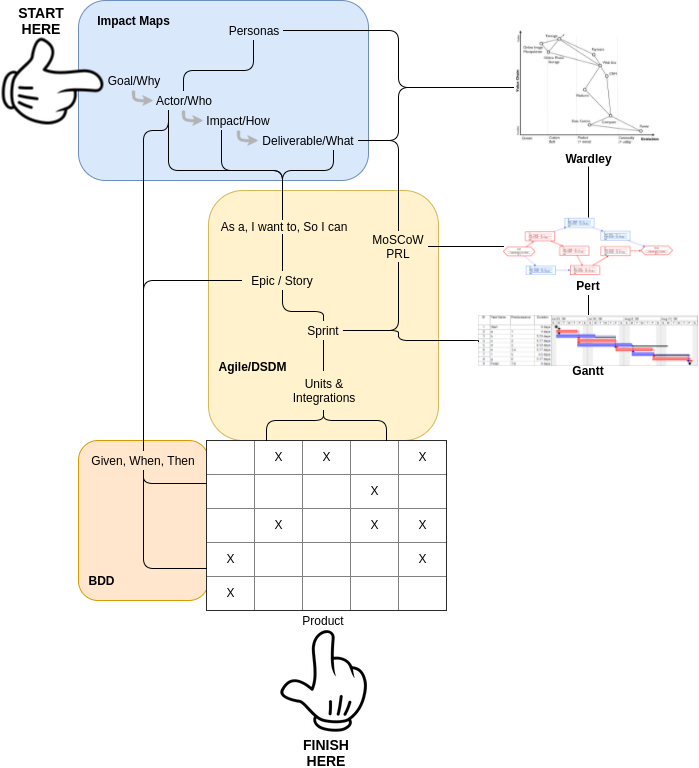
What could be simpler?